
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 인터페이스 추상클래스 차이
- 타임리프 기본기능
- 스프링
- erd editor
- HttpServletRequest
- 인터페이스
- 트러블슈팅
- 파이썬
- glob모듈
- 빈생명주기콜백
- Thymeleaf
- 추상클래스
- Python
- 인터페이스 추상클래스 비교
- Java
- erd툴
- 자바
- Spring
- Filter
- glob함수
- 네이버지도크롤링
- json사용법
- json사용
- 타임리프
- Servlet
- 요청데이터
- redirectattribute
- json모듈
- 스프링http
- 크롤링
- Today
- Total
개발하는 새우
[Spring] 빈 생명주기 콜백 - 꼬리에 꼬리를 물고 완벽 이해하기 본문
빈 생명주기 콜백
프로그램을 작성하면서 우리는 데이터베이스 커넥션 풀이나, 네트워크 소켓처럼 애플리케이션 시작 시점에 필요한 연결을 미리 해두고, 애플리케이션 종료 시점에 연결을 모두 종료하는 작업을 진행하려면, 객체의 초기화와 종료 작업이 필요하다. (Ex: 커넥션 풀의 connect & disconnect)
이해를 돕기 위해 네트워크에 연결하는 동작을 표현하는 NetworkClient 예제 클래스를 보겠습니다.
NetworkClient
public class NetworkClient {
private String url;
public NetworkClient() {
//NetworkClient를 생성하면 생성자가 호출된다.
System.out.println("생성자 호출 , url=" + url);
//NetworkClient 생성되면 네트워크 연결(connect() 호출)을 해준다.
connect();
//네트워크 연결 후 call() 메서드 실행
call("초기화 연결 메세지");
}
public void call(String msg) {
System.out.println("call= " + url + " message= " + msg);
}
public void connect() {
System.out.println("connect= " + url);
}
public void disconnect() {
System.out.println("close= " + url);
}
public void setUrl(String url) {
this.url = url;
}
}
BeanLifeCycleTest
import org.junit.jupiter.api.Test;
import org.springframework.context.ConfigurableApplicationContext;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
public class BeanLifeCycleTest {
@Test
public void lifeCycleTest() {
//스프링 컨테이너에 NetworkConfig.class 를 넣은 이후에 바로 Config 파일의 @Bean 메서드가 실행된다
ConfigurableApplicationContext ac = new AnnotationConfigApplicationContext(NetworkConfig.class);
NetworkClient client = ac.getBean(NetworkClient.class);
ac.close();
}
@Configuration
static class NetworkConfig {
@Bean
public NetworkClient networkClient() {
//@Bean 메서드가 실행으로 인해 networkClient 객체가 생성되기 때문에
//NetworkClient 생성자가 호출된다
NetworkClient networkClient = new NetworkClient();
networkClient.setUrl("http://hello-networktest.com");
return networkClient;
}
}
}
위의 예시를 결과로 확인해 보면 다음과 같이 url 값에 null이 들어가 있는 것을 확인할 수 있다.

당연한 결과이다. 이해하기 쉽게 실행 순서를 보면
(1) ApplicationContext을 통해 스프링 컨테이너가 생성된 후,
(2) 파라미터로 넘겨준 NetworkConfig.class 파일을 컴포넌트 스캔하여 그 안에 있는 @Bean 애노테이션이 붙어있는 메서드를 실행한다.
(3) NetworkClient 객체가 생성이 되고, 생성자가 호출되므로 url, connect, call 등등 호출하게 된다.
(4) 그 이후에 networkClient.setUrl 메서드가 실행이 되기 때문에 결과는 null이 나올 수밖에 없다.
스프링 빈은 객체를 생성 후 의존관계를 주입한 뒤 사용할 준비가 완료됩니다.
내가 해당 빈에서 초기화 작업들을(url 설정 등) 해주고 싶다면 이런 의존관계가 모두 주입된 다음 호출해야 합니다.
개발자 입장에서는 의존관계가 모두 주입이 완료되는 시점을 알기 위해서 스프링에서는 스프링 빈이 의존관계 주입이 완료되면 콜백 메서드를 통해 초기화 시점을 알려주는 기능을 제공합니다.
추가로 스프링 컨테이너의 소멸 직전 소멸 콜백을 주어서 스프링 컨테이너가 종료되기 전 로직을 수행할 수 있습니다.
(Ex: DB연결 종료)
스프링 빈 이벤트 라이프 사이클
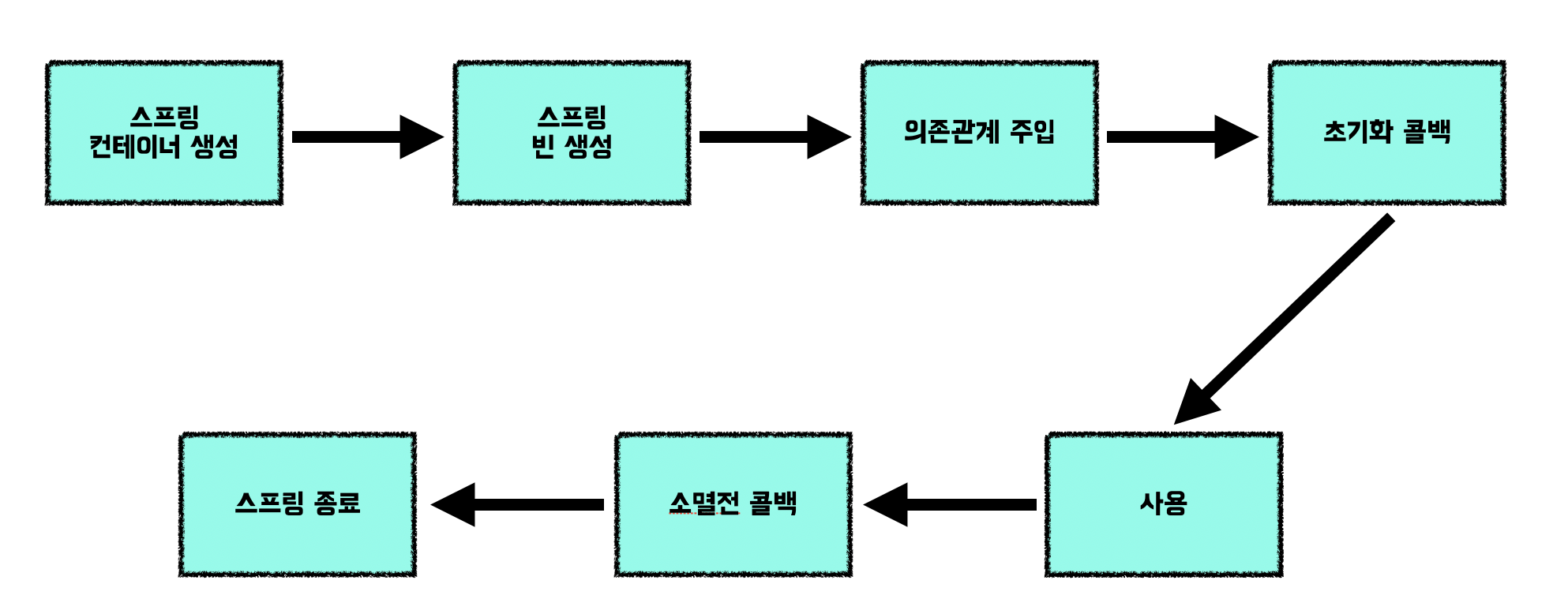
위와 같이 의존관계 주입이 일어난 후 "초기화 콜백",
사용 후 종료되기 직전에 "소멸전 콜백" 이 일어난다.
그럼 여기까지 공부하면서 몇 가지 의문점이 들 수도 있다.
잠깐 꼬리에 꼬리를 무는 궁금증을 풀어보겠다.
첫 번째로는
"아니 그렇다면 Url을 설정하는 setUrl 메서드를 생성자에 넣어서 생성자 주입을 통해 빈 생성과 초기화를 같이하면 되지 않을까요?" 라는 생각을 하실 수 있을것이다.
이에 대한 답으로는 객체의 생성과 초기화를 분리해야 합니다
객체의 생성과 초기화를 분리하자
생성자는 필수 정보를 받아 메모리 할당 후 객체를 생성하는 책임을 가집니다.
그리고 초기화는 이렇게 생성된 값들을 활용해 기타 무거운 작업들을 수행합니다.
그렇기에 생성과 초기화를 묶는 것은 SRP(단일 책임 원칙)을 위반하게 된다고 할 수 있기 때문에 명확하게 두 부분을 나누는 것이 유지 보수 관점 및 객체지향 프로그램 적으로도 좋습니다.
두 번째로는 제가 공부하면서 궁금해했던
"데이터베이스를 연결하고 소켓을 연결하고 만약에 애플리케이션 종료시점에 연결을 종료하지 않으면 어떻게 되나?"
위의 질문에 주요 문제점으로는 다음과 같습니다.
- 리소스 누수(Resource Leaks) : 연결이 종료되지 않으면, 사용되지 않는 리소스가 계속 시스템에 남아 있게 됩니다. 이로 인해 메모리 누수와 성능 저하를 초래할 수 있습니다.
- 성능 저하(Performance Degradation) : 자원이 충분히 회수되지 않으면, 점차 시스템의 반응 시간이 느려지고, 처리 능력이 저하됩니다. 예를 들어, 데이터베이스 커넥션 풀이 사용하고 종료되지 않아 가득 차게 된다면 새로운 요청이 대기 상태에 들어가거나 실패할 수 있습니다.
- 시스템 불안정(System Instability) : 사용 가능한 리소스 한계치에 도달하면 시스템이 불안정해질 수 있습니다. 이는 갑작스러운 시스템 중단을 초래하거나 예측 불가능한 오류가 발생할 수 있습니다.
- 비용 증가(Cost Increase) : 클라우드 환경에서는 사용한 리소스에 대해 비용을 지불하게 된다. 리소스가 제대로 종료되지 않으면 불필요한 비용이 발생할 수 있습니다.
스프링은 크게 3가지 방법으로 빈 생명주기 콜백을 지원합니다.
- 인터페이스 (InitializingBean, DisposableBean)
- 설정 정보에 초기화 메서드, 종료 메서드 지정(애노테이션 속성 설정)
- @PostConstructor, @PreDestroy 애노테이션 사용
인터페이스 InitializingBean, DisposableBean
첫 번째 방법은 바로 InitializingBean, DisposableBean 인터페이스를 구현하는 것입니다.
InitializingBean은 afterPropertiesSet() 메서드로 초기화를 지원합니다.
DisposableBean은 destroy() 메서드로 소멸을 지원합니다.
아래 코드를 통해 살펴보도록 하겠습니다.
public class NetworkClient implements InitializingBean, DisposableBean {
//...
@Override
public void afterPropertiesSet() throws Exception {
System.out.println("NetworkClient.afterPropertiesSet");
connect();
call("초기화 연결 메시지");
}
@Override
public void destroy() throws Exception {
System.out.println("NetworkClient.destroy");
disconnect();
}
}
afterPropertiesSet(), destroy() 스프링 빈 라이프사이클에서 의존관계 주입 이후에 afterPropertiesSet() 메서드가 호출이 되고 종료되기 직전에 destroy() 메서드가 호출이 되어 스프링이 초기화와 소멸을 지원해 줍니다.
초기화(InitializingBean), 소멸(DisposableBean) 인터페이스 단점
이 인터페이스는 스프링 전용 인터페이스입니다. 해당 코드가 스프링 전용 인터페이스에 의존하게 되는 것이죠.
초기화, 소멸 메서드의 이름을 변경할 수 없다는 단점이 있습니다. 인터페이스를 공부해 보신 분이라면 알겠지만 상위 클래스(인터페이스)를 구현하는 하위 클래스는 부모의 메서드 이름을 변경할 수 없는 거 아시죠?
내가 코드를 고칠 수 없는 외부 라이브러리에 적용할 수 없습니다.
참고로, 인터페이스를 사용하는 초기화, 종료 방법은 스프링 초창기에 나온 방법들이며 지금은 더 나은 방법들을 사용한다.
"스프링에 의존하면 안 좋은 건가요? @Autowired, @Bean 전부 스프링 전용 애노테이션인데..."
현재 우리는 2개의 클래스를 사용하고 있습니다.
설정 정보가 담긴 NetworkConfig와 일반 클래스인 NetworkClient 클래스이죠.
설정 정보에는 우리가 편하게 설정을 해주기 위해 스프링에 의존하여 @Bean, @Configuration 등이 사용되고 있습니다.
편한 설정을 위해 어쩔 수 없는 트레이드오프 같은 것이죠.
꼬리에 꼬리를 무는 트레이드 오프란?
일반적으로 서로 상반되는 두 가지 선택 사이에서 균형을 찾기 위해 어떤 것을 포기하면서 다른 것을 얻는 결정을 의미한다.
즉, 스프링에 의존하게 되지만 편리함이라는 실보다 득이 더 크기 때문에 사용한다고 생각하시면 됩니다.
하지만 위의 예제처럼 빈을 등록하고 그 이후에 초기화와 소멸을 위해 일반 클래스인 NetworkClient 클래스까지 스프링에 의존하게 됩니다.
만약, 스프링을 사용하지 않고 다른 프레임워크를 사용해야 한다면, 우리는 단지 설정정보뿐만 아니라 초기화해 주는 기능과 소멸 전 연결을 종료해 주는 기능 혹은 빈 자체의 구현이 스프링에 의존하기 때문에 스프링 코드를 걷어낸 후 다시 해당 프레임워크로 작성해주어야 하는 번거로움이 있는 것이죠.
그니까 쉽게 얘기하면 "우리는 스프링을 사용하지 않겠다!" 했을 때 우리는 설정 정보인 Config 파일을 싹 다 갈아엎고 다른 프레임워크를 사용하여 코드를 짜야하고, 추가로 스프링에 의존되어 있는 NetworkClient(빈 자체) 또한 싹 다 갈아엎고 다시 해당 프레임워크를 이용하여 코드를 작성해야 한다는 것이죠.
저도 공부하는 입장이라 제대로 정리를 잘 못한 거 같지만, 여기서의 주요 포인트는 설정 정보 외의 빈 자체의 구현도 스프링에 의존하고 있다는 문제입니다.
아직은 이해가 안 되더라도 아래 글을 쭉 보시면 이해가 될 수 있습니다.
설정 정보에서 초기화 메서드, 종료 메서드 지정(애노테이션 속성 설정)
설정 정보(Config)에 @Bean 애노테이션의 initMethod, destroyMethod 속성을 사용하여 초기화, 소멸 메서드를 지정할 수 있습니다.
아래 코드를 보시면 initMethod="init", destroyMethod="close"라는 값이 들어가 있는데요, 여기에 값은 개발자가(우리가) 알아서 정해주면 됩니다. 그리고 두 번째 코드처럼 해당 값 이름으로 메서드를 만들어주면 되는 것이죠.
설정 정보에 초기화 소멸 메서드 지정
class BeanLifeCycleTest {
//...
@Configuration
static class NetworkConfig {
//의존 관계 주입 이후 init 메서드 실행
//종료 직전 close 메서드 실행
@Bean(initMethod = "init", destroyMethod = "close")
public NetworkClient networkClient() {
NetworkClient networkClient = new NetworkClient();
networkClient.setUrl("http://hello-networktest.com");
return networkClient;
}
}
}
설정 정보를 사용하도록 변경
public class NetworkClient {
//...
public void init() {
System.out.println("NetworkClient.init");
connect();
call("초기화 연결 메시지");
}
public void close() {
System.out.println("NetworkClient.close");
disconnect();
}
}
설정 정보 사용의 특징은 아래와 같습니다.
- 메서드 이름을 자유롭게 줄 수 있다.
- 스프링 빈이 스프링 코드에 의존하지 않는다.
- 코드가 아니라 설정 정보를 사용하기 때문에 코드를 고칠 수 없는 외부 라이브러리에도 초기화, 종료 메서드를 적용할 수 있다.
종료 메서드 추론(@Bean의 destoryMethod 속성의 특징)
@Bean의 destroyMethod 속성에는 아주 특별한 기능이 숨어져 있습니다.
라이브러리는 대부분 close, shutdown이라는 이름의 종료 메서드를 사용한다고 합니다.
@Bean의 destroyMethod는 기본값이 (inferred) (추론)으로 등록되어 있습니다.
실제로 아래와 같이 파고 들어간다면 확인해 볼 수 있습니다.


이 추론 기능은 close, shutdown이라는 이름의 메서드를 자동으로 호출해 줍니다.
이름 그대로 종료 메서드를 추론해서 호출해 줍니다.
따라서 직접 스프링 빈으로 등록하면 종료 메서드는 따로 적어주지 않아도 알아서 close, shutdown의 이름을 가진 메서드를 찾아서 실행시켜 주는 것이죠.
만약에 이 추론 기능을 사용하기 싫다면 destroyMethod=""처럼 빈 공백을 지정해 주시면 됩니다.
@PostConstruct, @PreDestory 애노테이션
import jakarta.annotation.PostConstruct;
import jakarta.annotation.PreDestroy;
public class NetworkClient {
//...
@PostConstruct
public void init() {
System.out.println("NetworkClient.init");
connect();
call("초기화 연결 메시지");
}
@PreDestroy
public void close() {
System.out.println("NetworkClient.close");
disconnect();
}
}
설정 정보는 처음 그대로
class BeanLifeCycleTest {
//...
@Configuration
static class NetworkConfig {
@Bean
public NetworkClient networkClient() {
NetworkClient networkClient = new NetworkClient();
networkClient.setUrl("http://hello-networktest.com");
return networkClient;
}
}
}
@PostConstruct, @PreDestroy 이 두 애노테이션을 사용하면 가장 편리하게 초기화와 종료를 실행할 수 있습니다.
다음은 @PostConstruct, @PreDestroy 애노테이션들의 특징입니다.
- 최신 스프링에서 권장하는 방법입니다.
- 애노테이션 하나만 붙이면 되므로 매우 편리합니다. 초기화 메서드에는 @PostConstruct 애노테이션을, 종료 메서드에는 @PreDestory 애노테이션을 붙여주면 된다.
- 해당 애노테이션의 패키지를 보면 jakarta.annotation.PostConstruct이다. 즉, 스프링에 종속적인 기술이 아니라 자바 표준 기술이다. 따라서 스프링이 아닌 다른 컨테이너에서도 동작한다.
- 유일한 단점으로는 외부 라이브러리에는 적용하지 못한다. 외부 라이브러리를 초기화, 종료해야 하면 @Bean 속성의 기능을 사용하도록 하자.
인프런의 김영한 님의 스프링 기본 강좌를 듣고 배운 지식과 추가로 인터넷을 통해 여러 블로그를 통해 공부한 지식, 그리고 궁금했던 점을 혼자 정리해서 블로그에 정리를 하다 보니 올바르지 않은 지식이 있을 수도 있습니다.
틀린 부분 있으면 댓글을 통해 알려주시면 고쳐나갈 수 있도록 하겠습니다.
이 글을 통해 배운 점이나 깨달은 점이 조금이라도 있다면 성공적인 포스팅이라 할 수 있을 거 같습니다.
출처(참고)
https://catsbi.oopy.io/3a9e3492-f511-483d-bc65-183bb0c166b3
https://dev-coco.tistory.com/170#head3
김영한님의 스프링 핵심 원리 - 기본편
똑똑한 챗GPT 4.0
'Spring | Spring Boot' 카테고리의 다른 글
| [Spring] 빈 스코프(Bean Scope) 완벽하게 이해하기 (1) | 2024.04.30 |
|---|---|
| [Spring] 싱글톤 패턴이란? 그리고 스프링에서의 싱글톤 (0) | 2024.04.25 |
| [Spring] 스프링과 스프링부트(Spring Boot) (1) | 2024.04.20 |
| [Spring] IoC(제어의 역전)와 DI(의존성 주입)의 완벽 이해 (0) | 2024.03.20 |
| [Spring] 스프링(Spring)이란? (0) | 2024.03.20 |



